
type
status
date
slug
summary
AI summary
AI translation
tags
category
password
icon
By registering an account on OKX Crypto Exchange using the invitation link from blackcat1402, you can enjoy several benefits. These include a 10% rebate on spot contract trades, a 20% discount on fees, permanent access to blackcat1402 Membership and Advanced Indicators, free internal testing of the Advanced Trading System, and exclusive services such as member technical indicator customization and development.
OKX Crypto Exchange blackcat1402 invitation registration link:


Source: Quantum Bit


Various large models have rolled up their context windows. Llama-1 used to come standard with 2k, but now it's embarrassing to go out with anything less than 100k.
However, a extreme test revealed that most people are not using it correctly and are not leveraging the full potential of AI.
Can AI really find specific key facts from hundreds of thousands of words? The redder the color, the more mistakes AI makes.
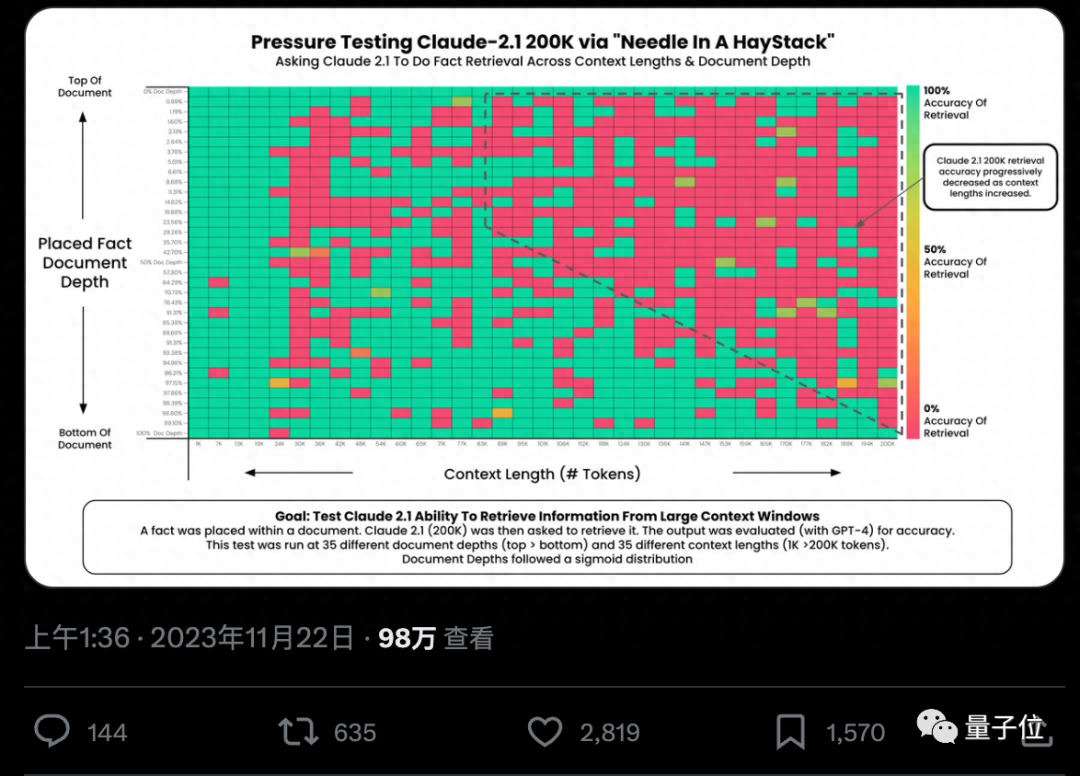
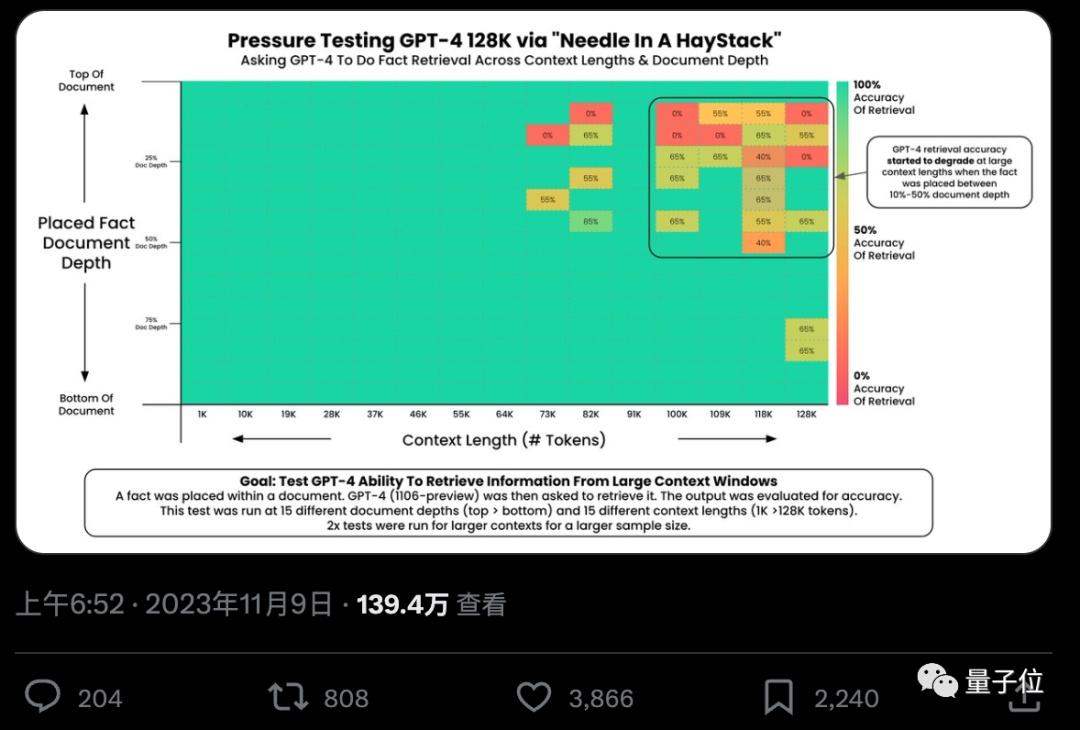
By default, both GPT-4-128k and the latest released Claude2.1-200k models do not perform well. However, after understanding the situation, the Claude team provides an extremely simple solution that can directly improve the performance from 27% to 98%.
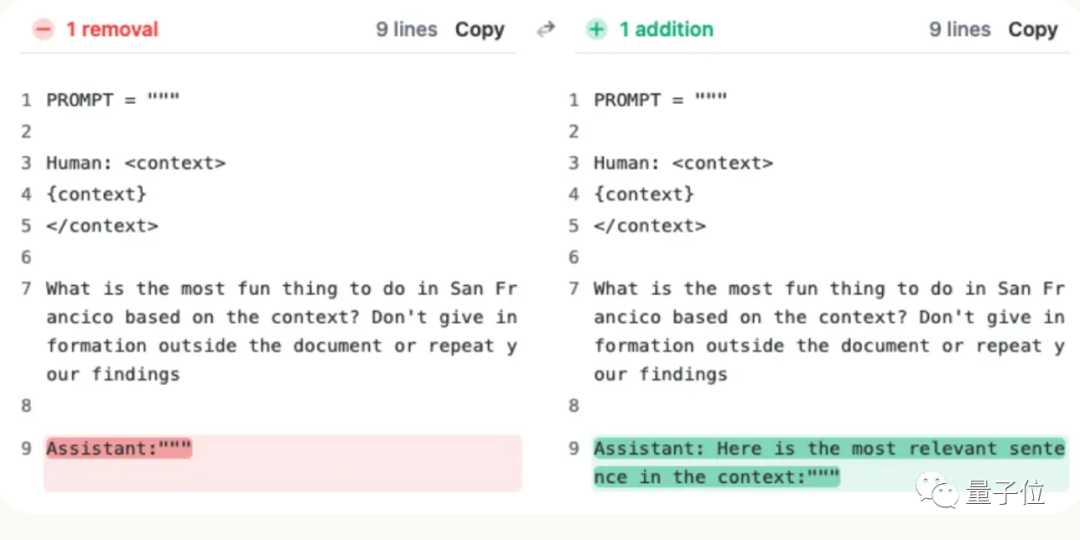
Just add this sentence not on the user's query, but let the AI say it at the beginning of the reply:
“Here is the most relevant sentence in the context:”
(这就是上下文中最相关的句子:)
Finding a Needle in a Haystack with Large Models
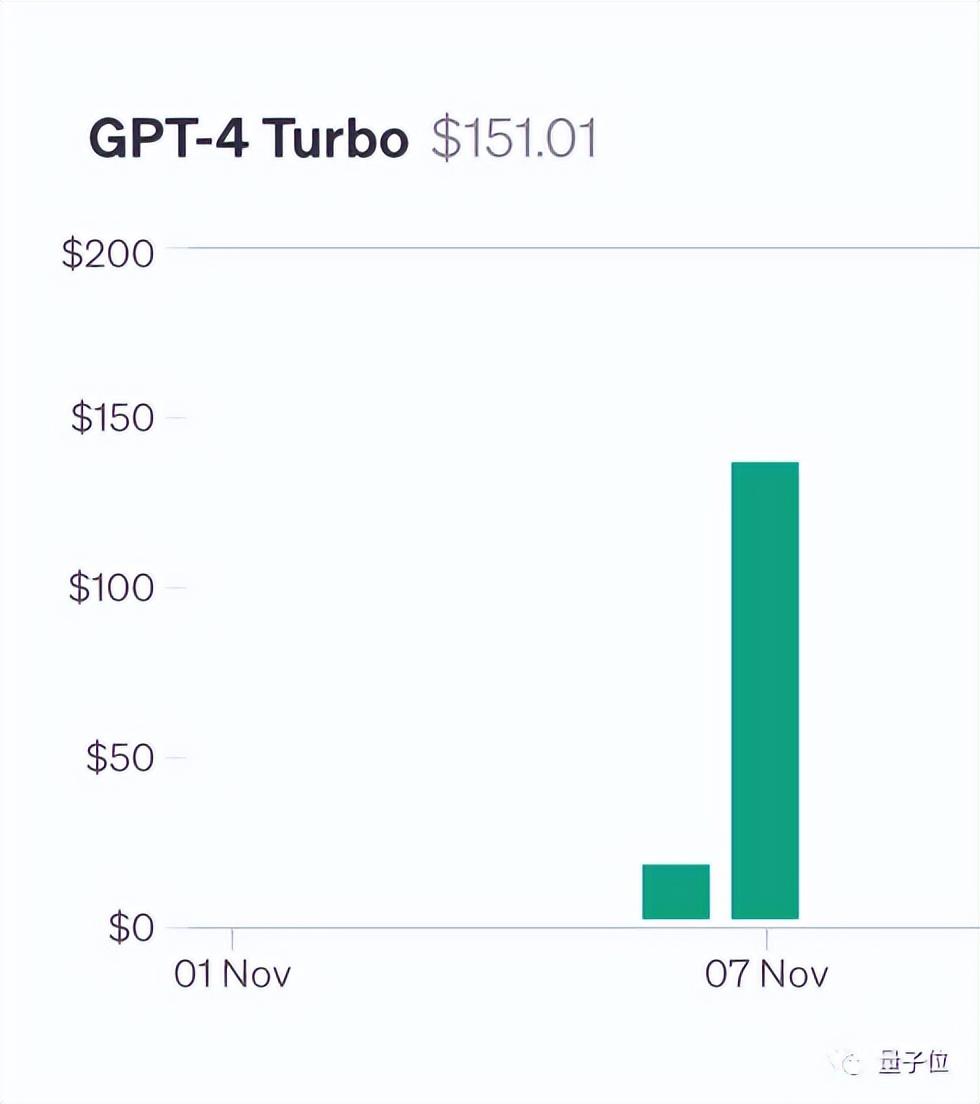
To conduct this test, author Greg Kamradt spent at least $150 out of his own pocket.
Fortunately, when testing Claude2.1, Anthropic stepped in to lend a hand and provide him with a free quota, otherwise he would have had to spend an additional $1016.
Actually, the testing method is not complicated. It involves using 218 blog posts by YC founder Paul Graham as test data.
Add specific statements at different positions in the document: The best thing in San Francisco is sitting in Dolores Park on a sunny day and enjoying a sandwich.
Please have GPT-4 and Claude2.1 use only the provided context to answer questions, and repeatedly test them with different context lengths and positions in the document.

Finally, use the Langchain Evals library to evaluate the results.
The author named this set of tests "Finding a Needle in a Haystack/Fishing in the Ocean" and open-sourced the code on GitHub. It has received 200+ stars and it was revealed that a company has sponsored the testing of the next large model.
LLMTest_NeedleInAHaystack
gkamradt • Updated Dec 22, 2023
AI Company Finds Its Own Solution
After a few weeks, Claude's company, Anthropic, carefully analyzed the situation and discovered that the AI was simply reluctant to answer questions based on individual sentences in the document, especially when these sentences were inserted later and had little relevance to the overall article.
In other words, the AI determined that these sentences were unrelated to the main topic of the article, and therefore took shortcuts by not searching through them one by one.

Here is the most relevant sentence in the context: This is when you need to trick the AI a bit, by asking Claude to add the sentence "Here is the most relevant sentence in the context:" at the beginning of their answer. This will solve the problem.
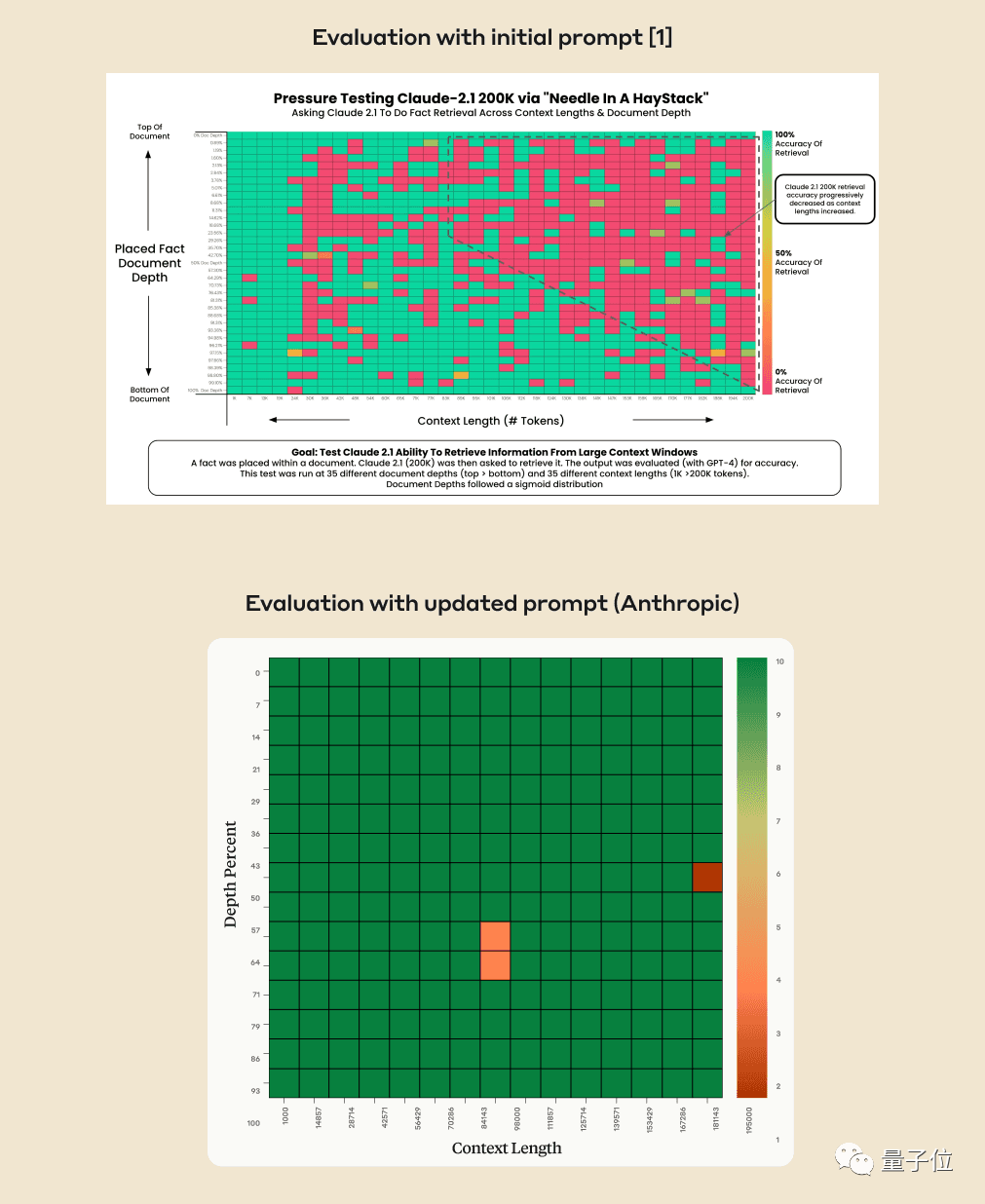
Using this method can also improve Claude's performance when searching for sentences that were not added later by humans and were originally present in the original article.
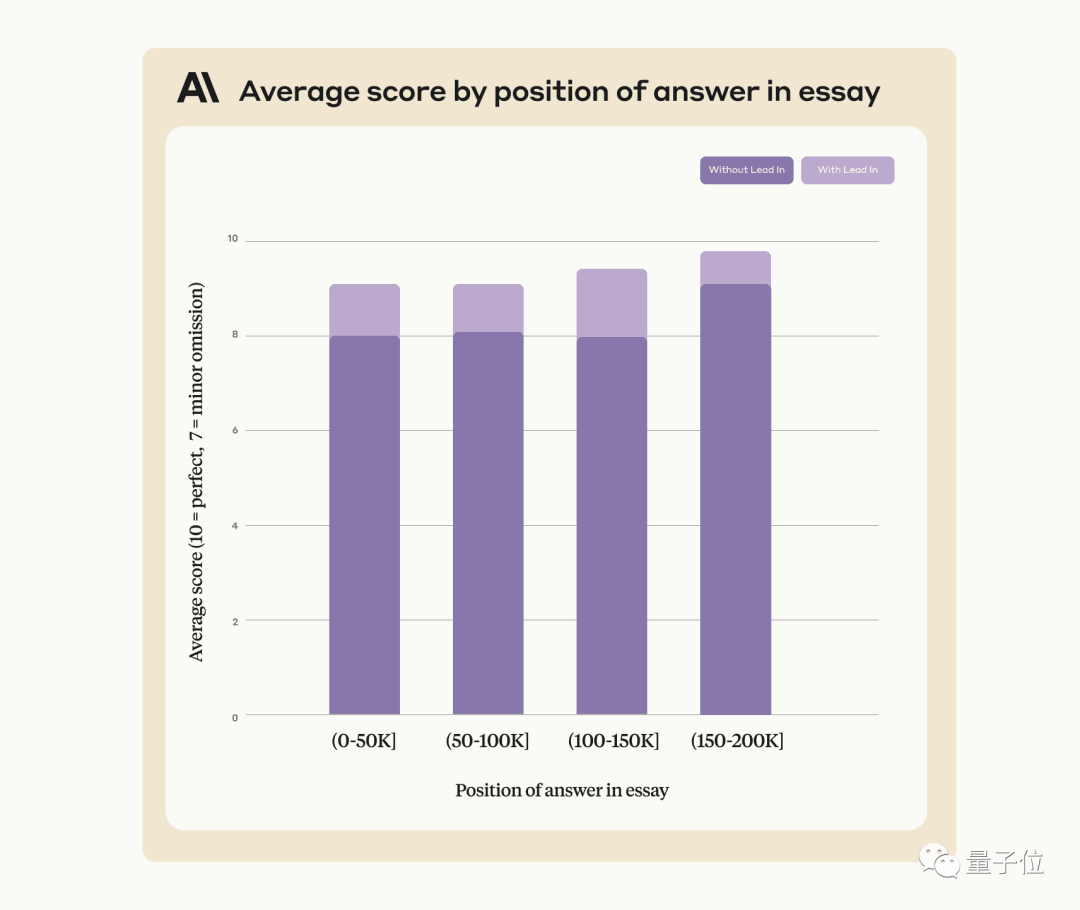
Anthropic company stated that they will continue to train Claude in the future to make it more adaptable to such tasks.
During API calls, the AI is required to start the response with a specified prompt, among other clever uses.
Entrepreneur Matt Shumer added a few additional tricks after reviewing this plan:
If you want the AI to output in pure JSON format, end the prompt phrase with "{". Similarly, if you want the AI to list Roman numerals, simply end the prompt phrase with "I:".
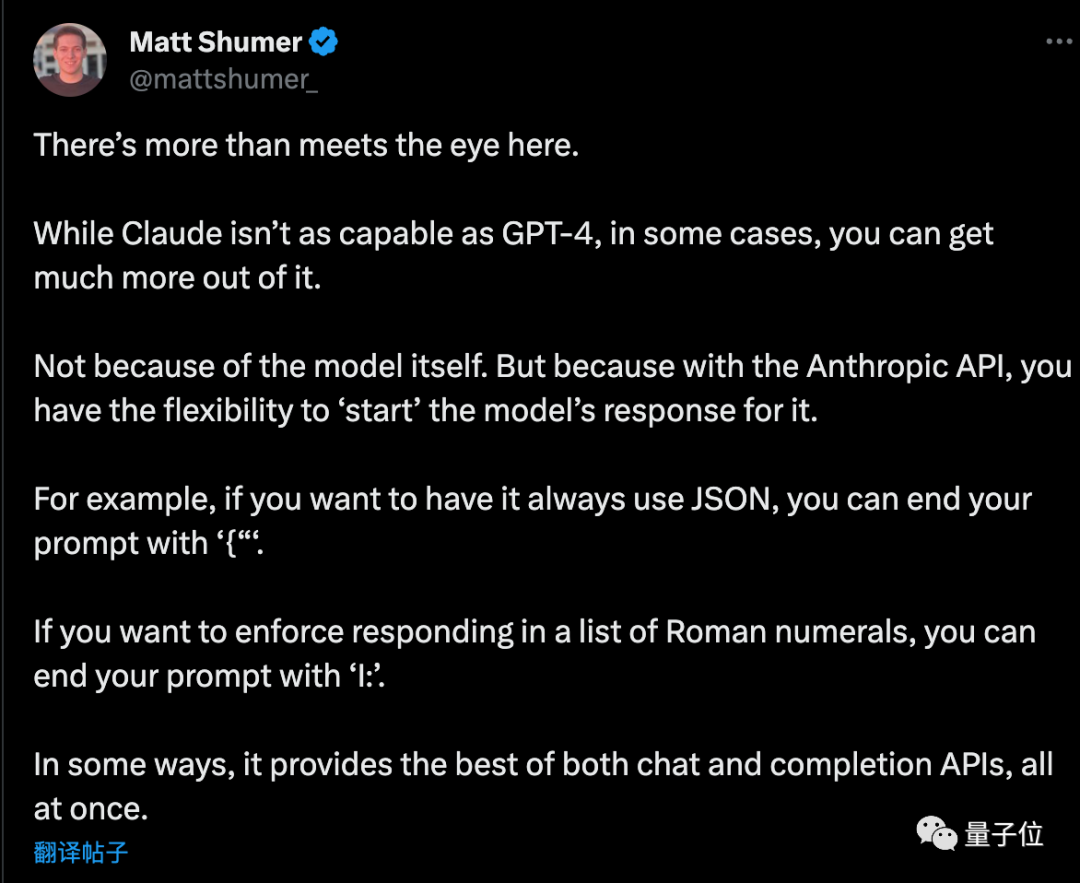
But the matter is not over yet...
Domestic large-scale model companies have also noticed this test and started to try if their own large-scale models can pass.
The Moon's Dark Side Kimi Large Model team, which also has a super long context, has also identified issues in their test but has provided different solutions and achieved good results.

In this way, modifying the user's prompt is easier than requiring the AI to add an additional sentence to its response, especially when using a chatbot product directly instead of calling an API.
I also tested the dark side of the moon with my new method for GPT-4 and Claude2.1. The results showed significant improvement for GPT-4, while Claude2.1 only had a slight improvement.
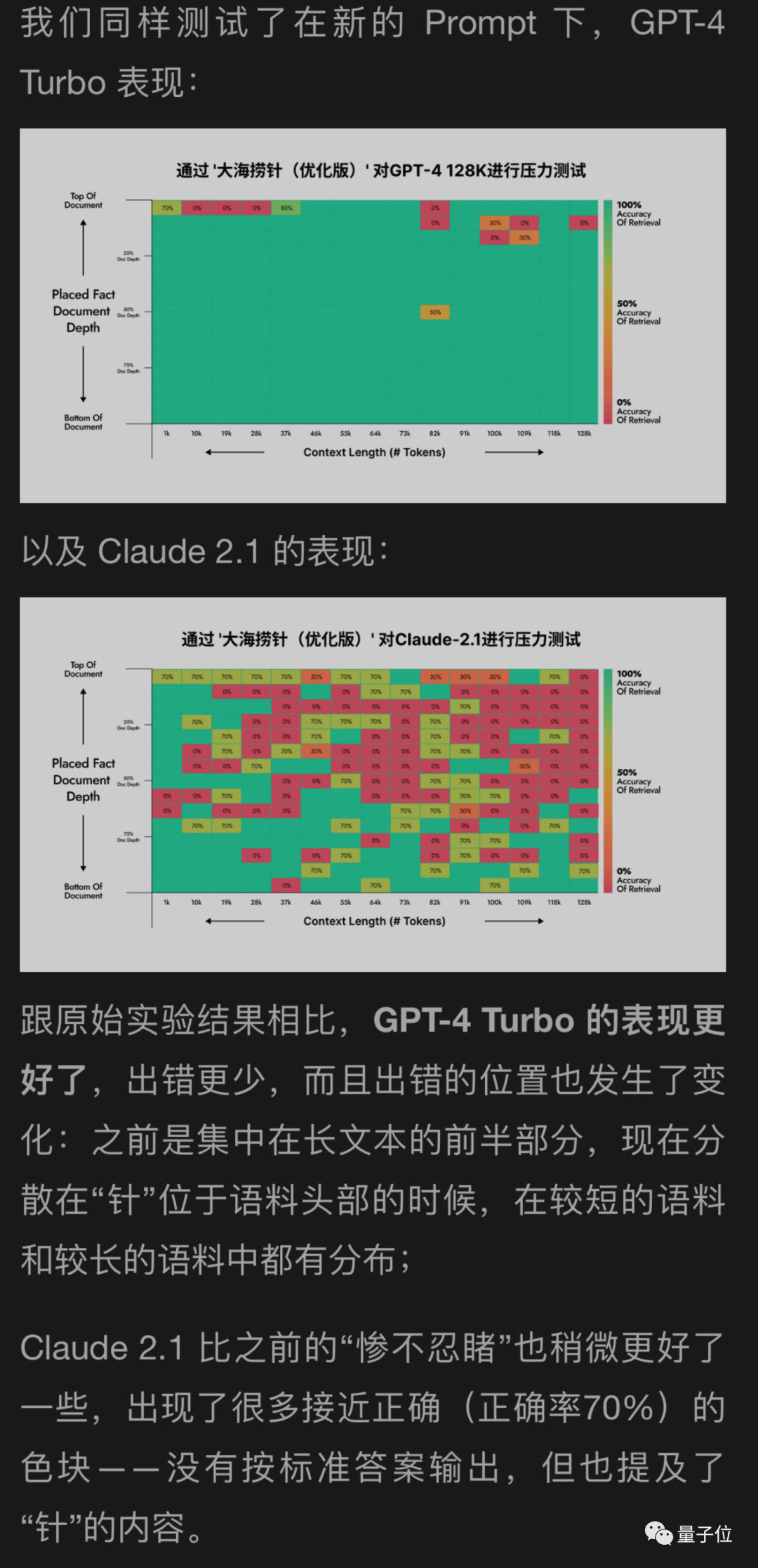
It appears that this experiment itself has certain limitations, and Claude also has his own uniqueness, which may be related to their own alignment method, Constituional AI. It would be better to use the methods provided by Anthropic themselves.
Later, the engineers on the dark side of the moon conducted more rounds of experiments, and one of them was unexpectedly...

Reference link:
- Author:blackcat1402
- URL:https://www.tradingview.com/u/blackcat1402//article/ai-context-power-en
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts